I. Introduction
Dimensionality Reduction
high-dimensional data$\qquad \rightsquigarrow \qquad \underbrace{\textit{lower-dimensional data}}_{\text{easier to visualize}}$
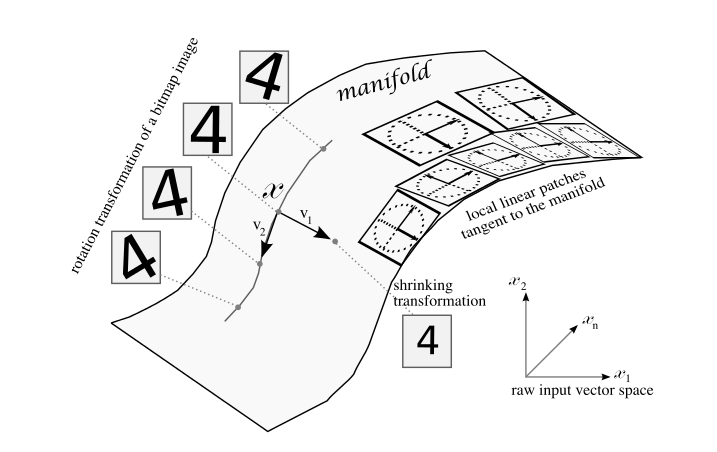
Manifold hypothesis: real-world high-dimensional data vectors lie in a lower-dimensional embedded manifold.
II. Principal component analysis (PCA)
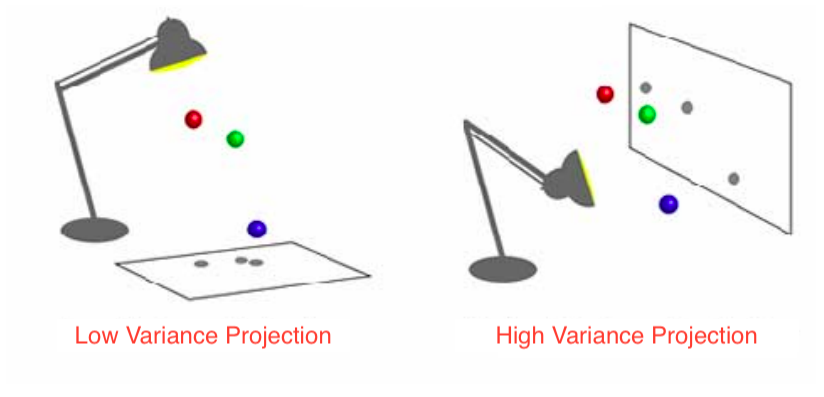
Goal: Find orthogonal axes onto which the variance of the data points under projection is maximal, i.e. find the best possible “angles” from which the data points are the most spread out.
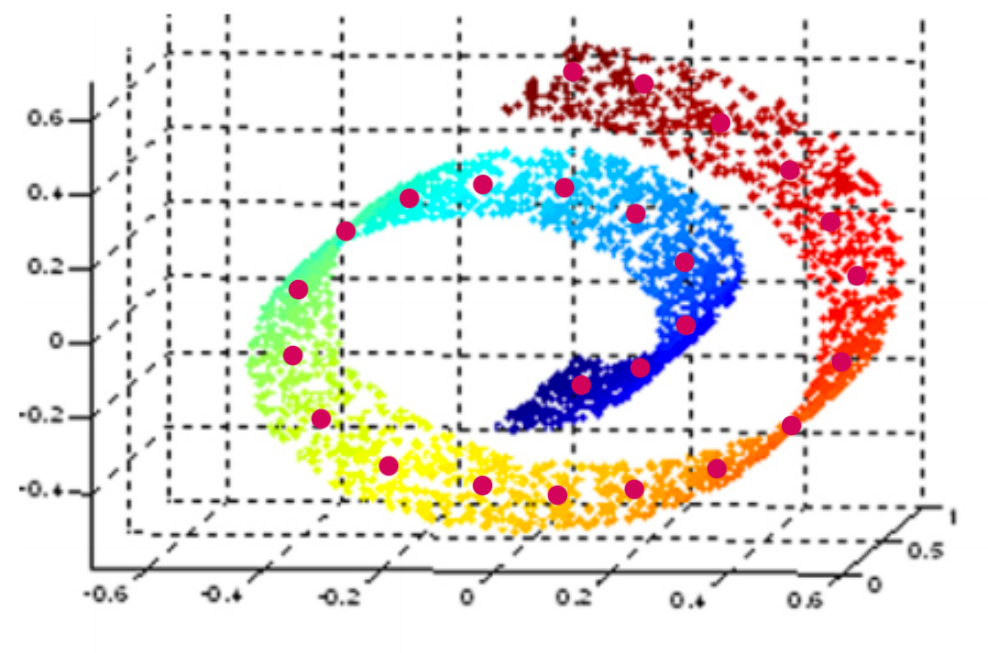
III. Isomap
Goal: MDS but curvature of the data space taken into account
- ⟶ geodesic distance:
- length of paths on curved manifold surfaces are measured as if they were flat
t-Distributed Stochastic Neighbor Embedding (t-SNE)
Map points are:
- attracted to points that are near them in the data set
- repelled by points that are far from them in the data set
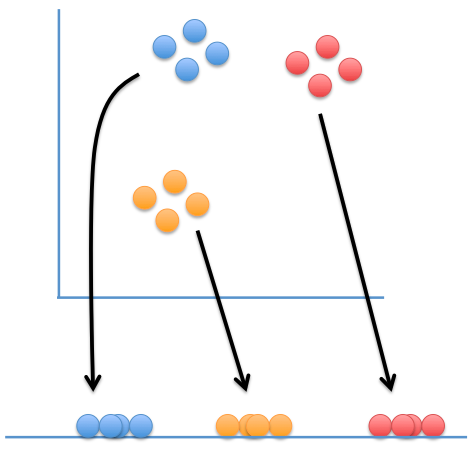
Image courtesy of statquest.org
Step 1
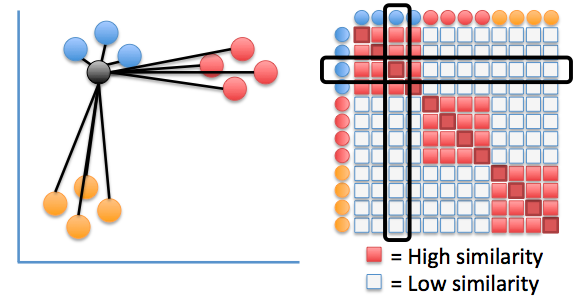
probability that $x_i$ has $x_j$ as its neighbor if neighbors were chosen according to a Gaussian distribution centered at $x_i$
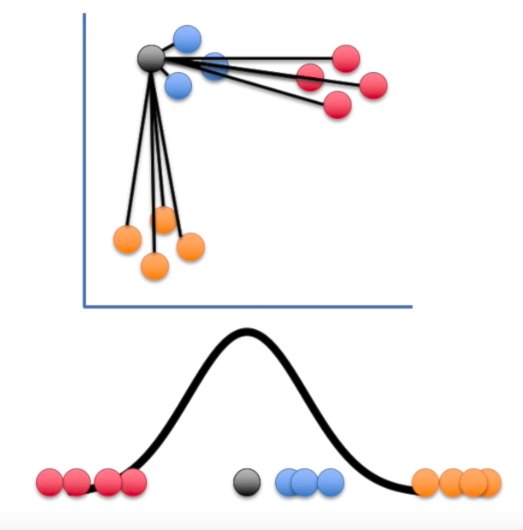
Step 2
Step 3
-
$y_i$'s initialized at random
-
Similarities between visualization points:
$$q_{i,j} ≝ \frac{(1+\vert\vert y_i-y_j\vert\vert^2)^{-1}}{\sum_{k\neq l}(1+\vert\vert y_i-y_l\vert\vert^2)^{-1}}$$⟶ computed with resort to a Student-$t$ distribution
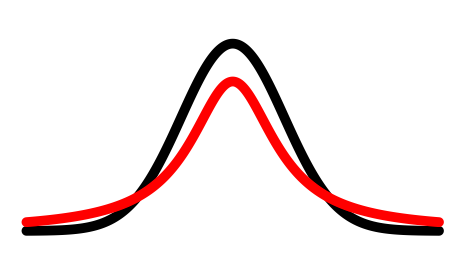
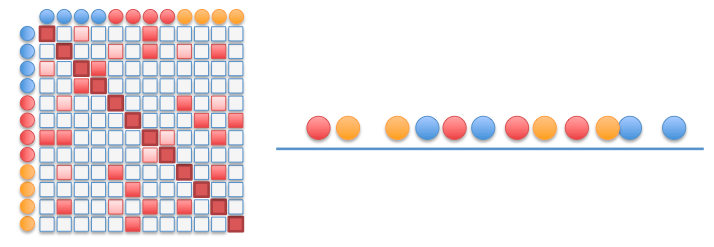
Step 4
-
Minimize the Kullback–Leibler divergence: $C ≝ \sum_{i≠ j}p_{ij}\log {\frac {p_{i,j}}{q_{i,j}}}$, by modifying the $y_i$'s with gradient descent
-
Recompute the $q_{i,j}$'s at each step (until convergence is reached)
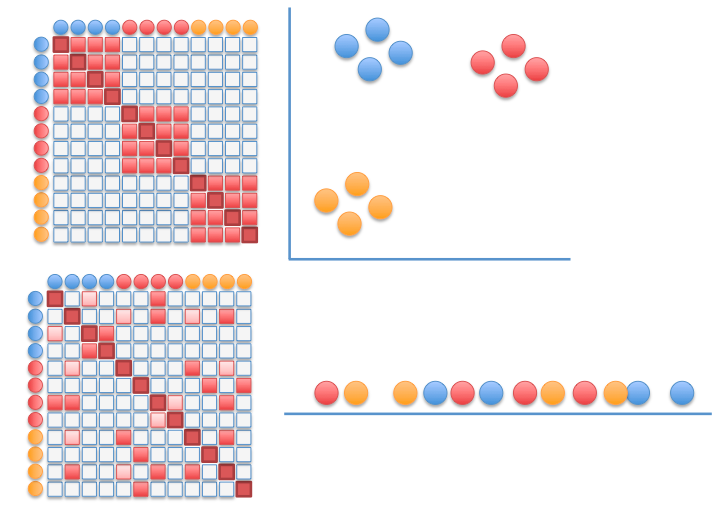
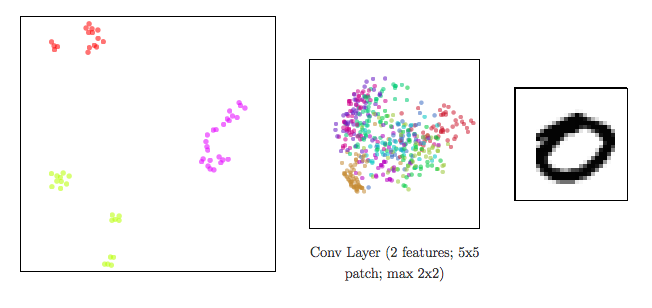
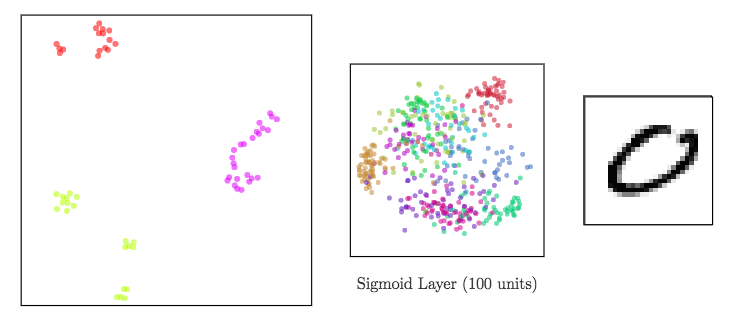
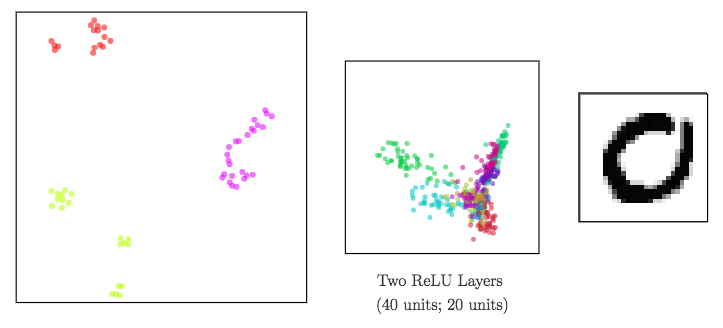
Dimensionality reduction to visualize high-dimensional representations
In a neural network:
- input data ⟶ shape changed from a layer to another: a representation is the reshaped data at a given layer.
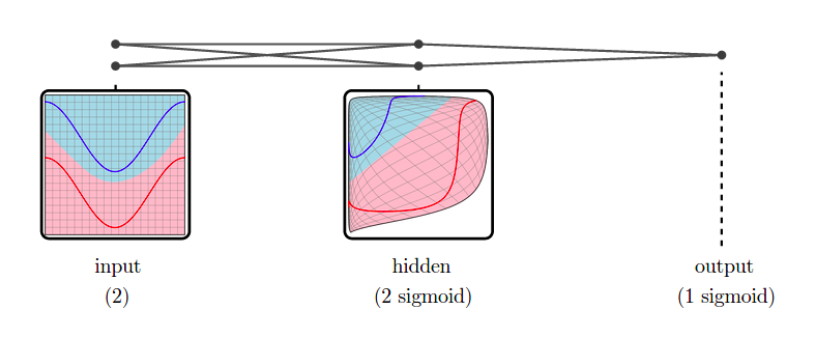
Since representations are high-dimensional ⟹ DR methods to visualize them
Sigmoid
ReLU
CNN