Week 4: Large Language Models
Week 4: Large Language Models
Younesse Kaddar
Philosophy Seminar, University of Oxford
Topics in Minds and Machines: Perception, Cognition, and ChatGPT
Recap of Last Week’s Session
- Foundations and milestones of Deep Learning
- Architecture and functioning of Neural Networks
- Backpropagation algorithm
- Bias-Variance Tradeoff
- Optimizers and Learning Rate Schedulers
- Adversarial Attacks
- Understanding Neural Networks through visualizations
This week:
- Semi-supervised learning as the “dark matter of intelligence” (Yann LeCun)
- “Attention is all you need”: the Transformer architecture
- From Transformers to Large Language Models (LLMs) like ChatGPT
- Mechanistic interpretability
- Prompt engineering
- Shoggoth and “AI doomers”
- Theory of mind for LLMs
- Philipp and Vincent’s paper: Humans in Humans Out
1. “Dark Matter of Intelligence”
Self-Supervised Learning (SSL)
Model trained on unlabeled data: learns to predict missing parts of the input data (eg. next word in a sentence or part of an image)
Advantages over supervised learning:
- Does not require labeled data (expensive, time-consuming and not easily available)
- Can be used to train models on very large datasets (better performance)
⟶ Yann LeCun: “Dark Matter of Intelligence”
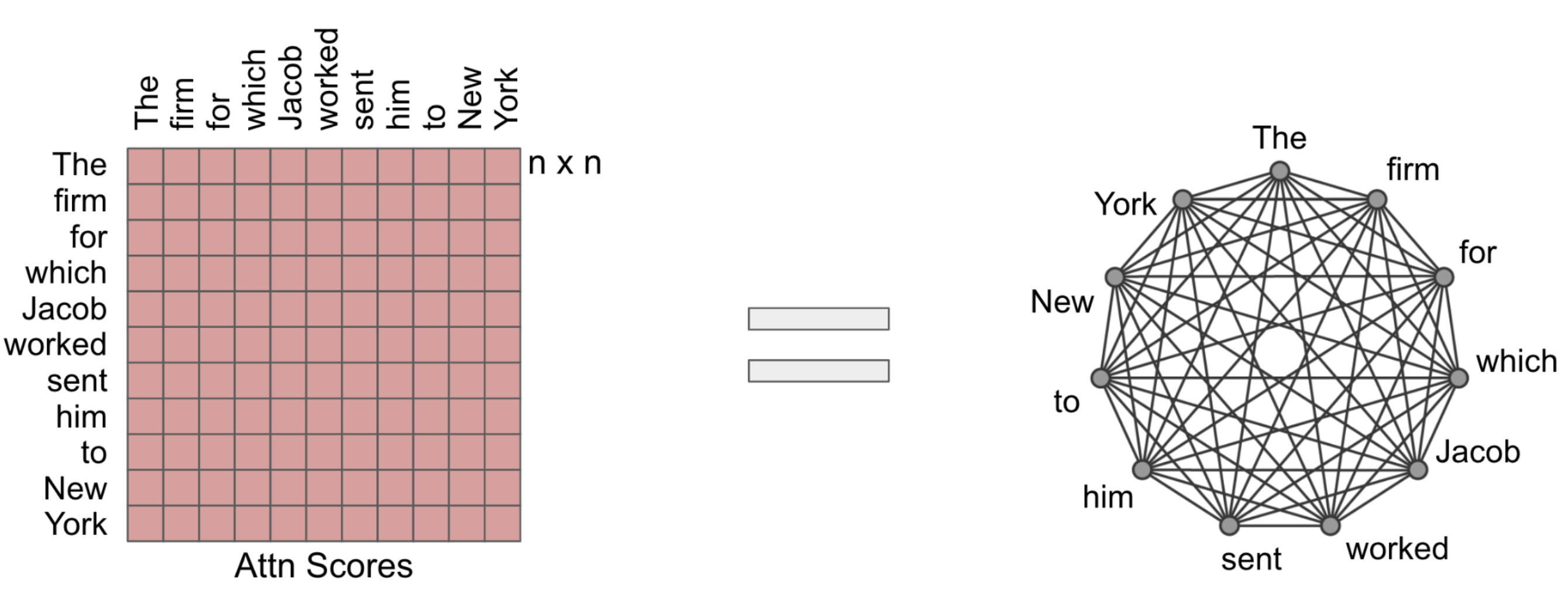
2. Introduction to Attention Mechanism
- Focus on relevant parts of input data to make decisions
- Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau, Cho, Bengio, 2014)
- Improves performance in tasks like machine translation and sequence-to-sequence learning

Self-attention: Key Components
- Query, Key, and Value vectors
- Attention scores and weights
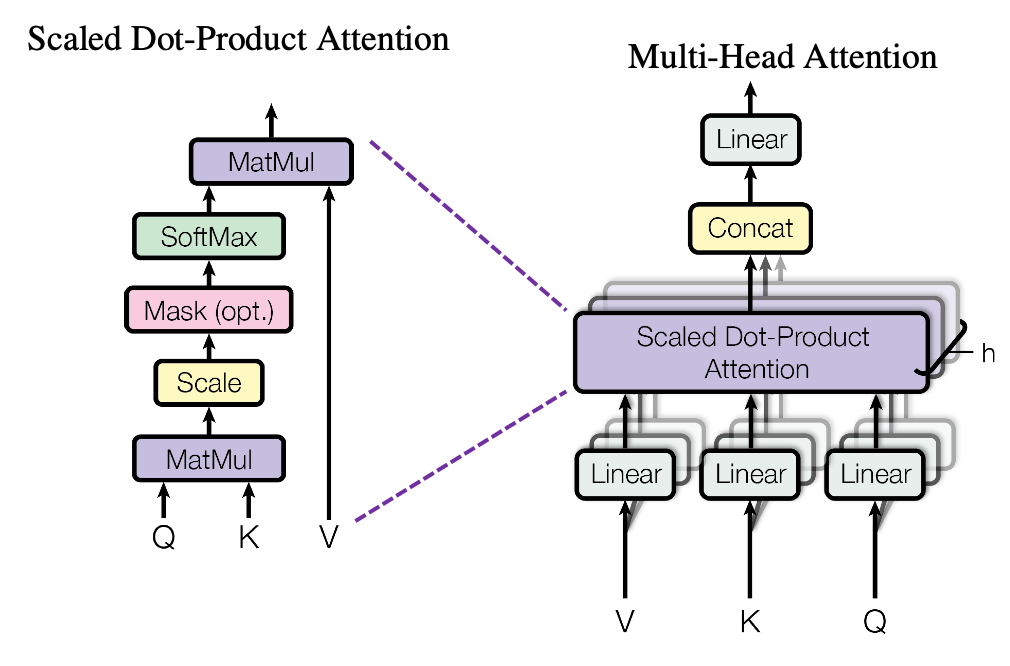
Benefits:
- Better handling of long-range dependencies
- Improved interpretability of model decisions
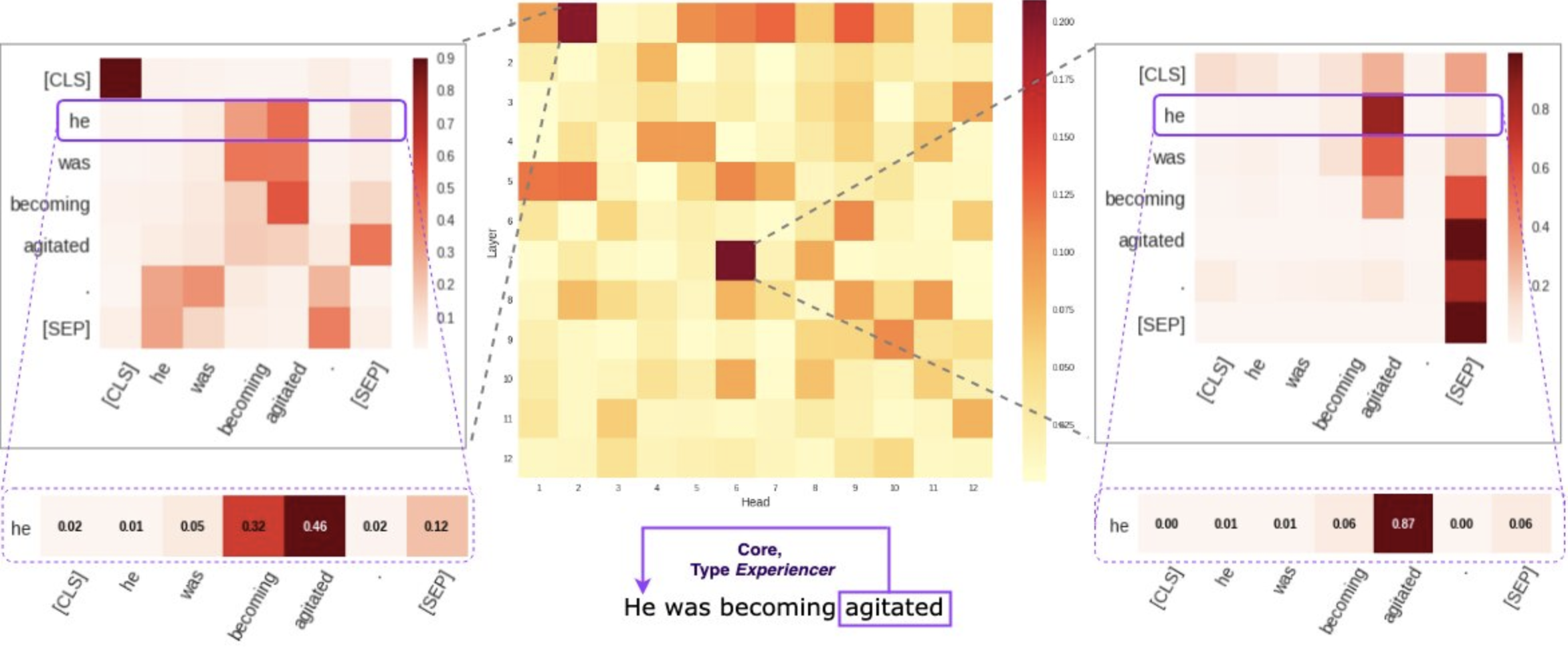
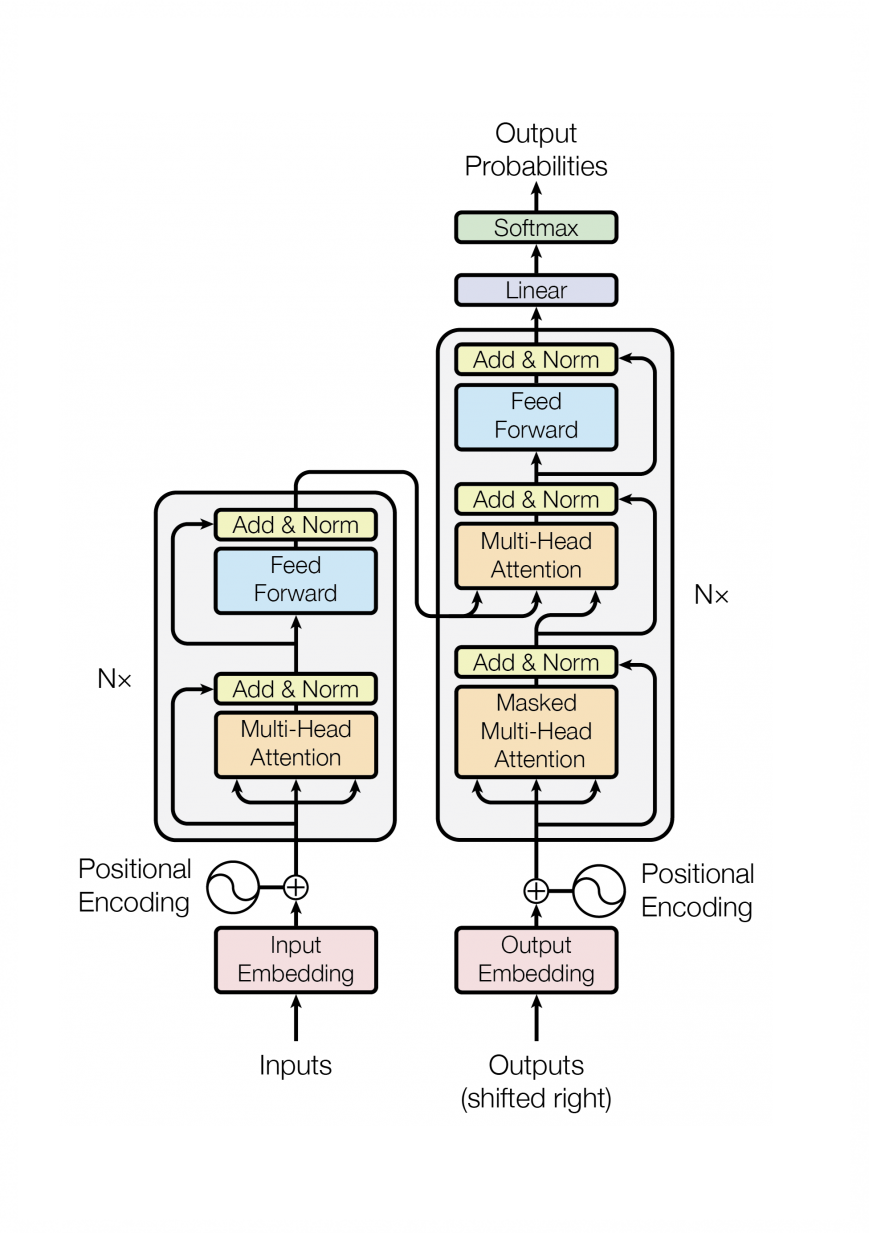
3. “Attention is all you need”: Transformer Architecture
- “Attention is All You Need” (Vaswani et al., 2017)
- Revolutionized NLP, unified NLP and Computer Vision
- Recurrent and Convolutional layers ⟶ replaced by self-attention
- Key Components:
- Multi-head attention block
- MLP block
- Residual path and Layer Normalization
The Math, Reminder: MLP
\[z_j ≝ \sum_{i=1}^n w_{ij} x_i + b_j \qquad o_k ≝ \sum_{j=1}^m w_{jk} σ(z_j) + b'_k\]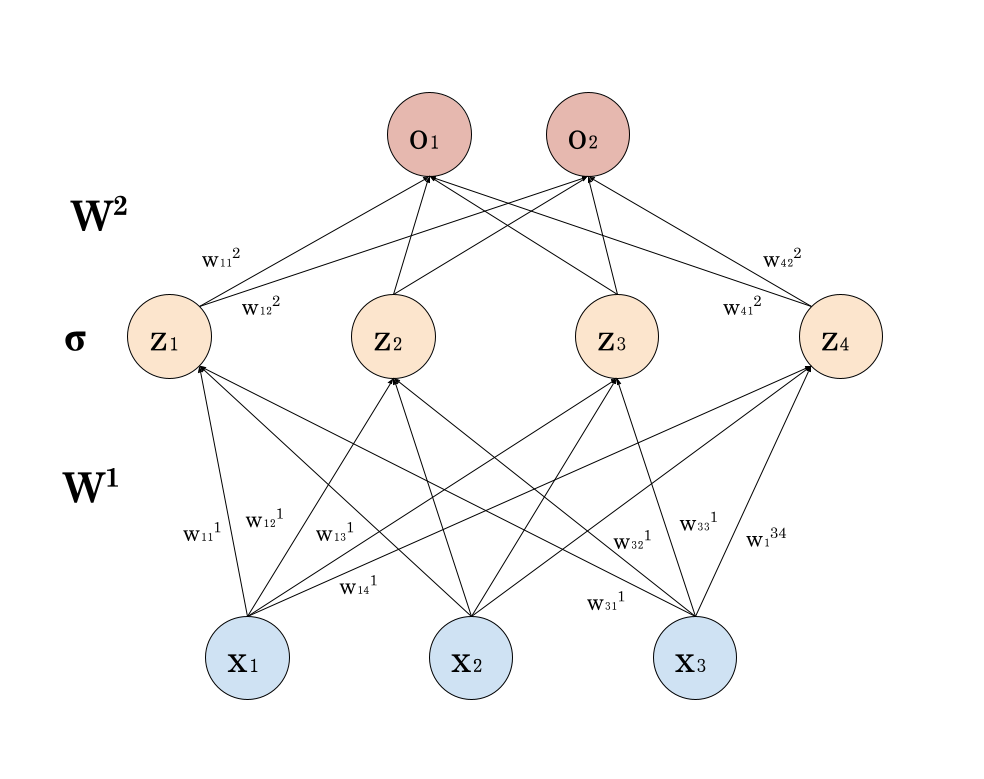
If $X$ is the design matrix, the NN (without the bias terms) is given by:
\[σ(X W^1) W^2\]
The Math, Transformer
- Multi-head attention block
- \[σ\big(X W_Q (X W_K)^T\big) X W_V = σ\big(X W_Q W_K^T X^T\big) X W_V\]
- MLP block:
- \[σ(X W^1) W^2\]
- Layer Normalization:
- Every row of $X$ is normalized to have mean $0$ and variance $1$ (up to learned scaling and shifting parameters)
- Skip connection: we keep adding to the residual path
- $X + \text{MHA}(X)$
- $X + \text{MLP}(X)$
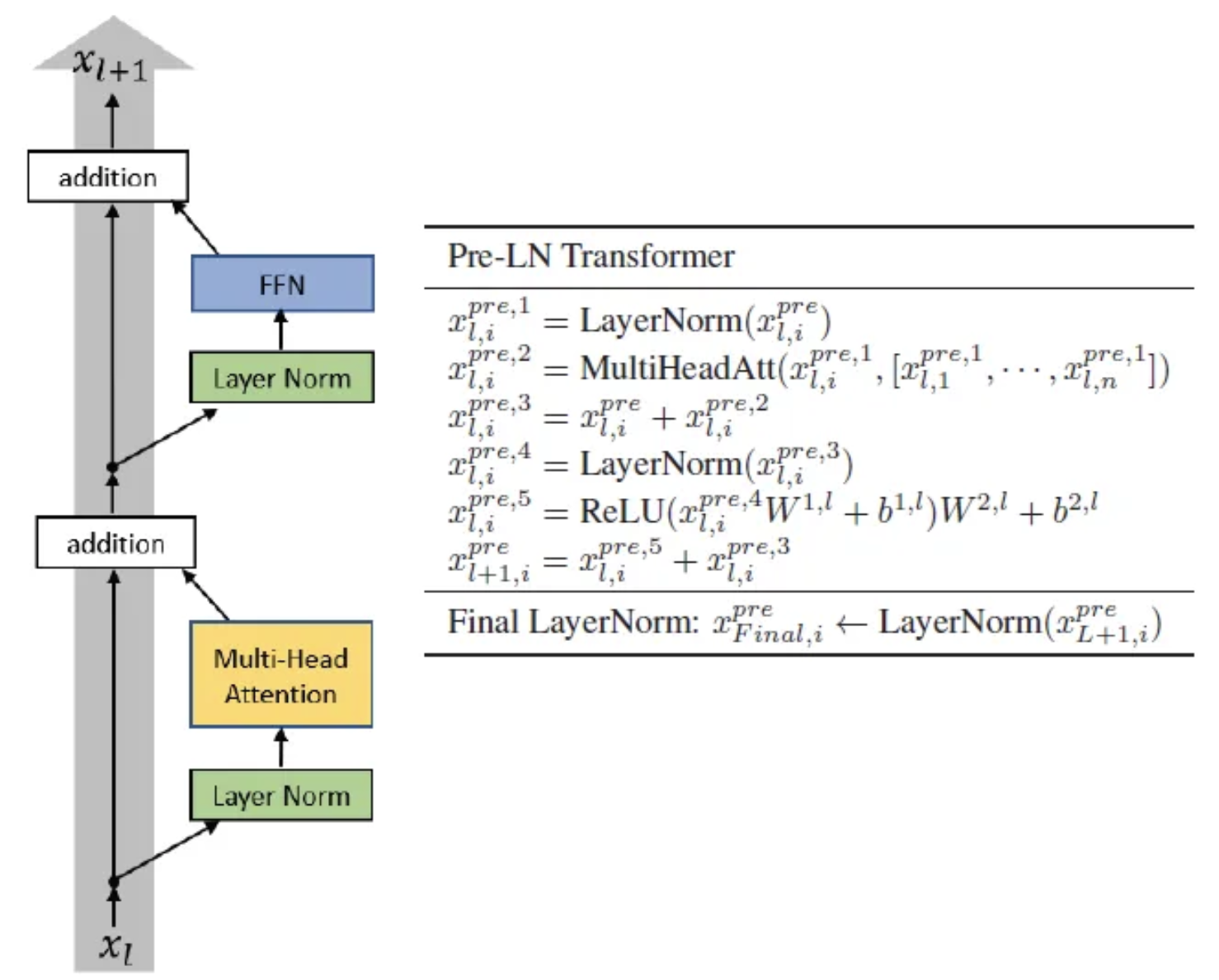
Pre-Layer Normalization
On Layer Normalization in the Transformer Architecture (Xiong, 2020)
Transformers: Special case of Graph Neural Networks
- Graph Neural Networks (GNNs)
- NNs operating on graph-structured data
- Transformers: special case of GNNs. Unordered sequence ⟺ a complete graph
-
Similarities: Message-passing-like architectures
- Differences: Transformers for sequence data (self-attention), GNNs for arbitrary graph structures
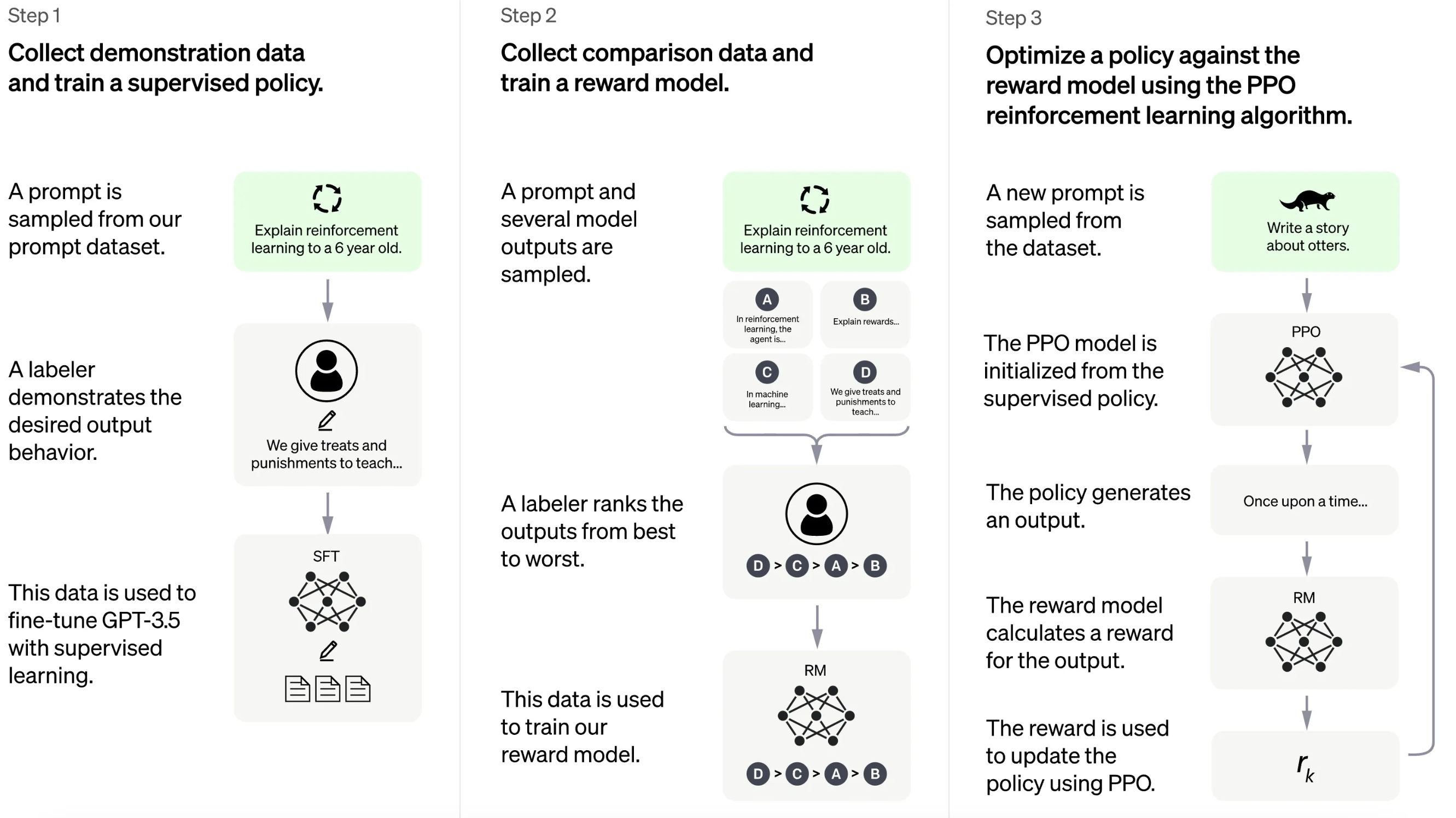
4. From Transformers to Chat Large Language Models (LLMs)
Example: ChatGPT
-
Fine-tuned for conversational AI tasks
-
Further trained with Reinforcement Learning from Human Feedback (RLHF)
PEFT, Adapters, and LoRA
- Parameter-Efficient Fine-Tuning (PEFT)
- Fine-tuning method for Large Language Models (LLMs).
- Reduces computation and resource requirements, uses adapters.
- Adapters
- Small, specialized modules enhancing LLM performance for specific tasks.
- Trained on task-specific data.
- Faster and cheaper to train compared to entire LLMs.
- LoRA (Low-Rank Adapters)
- Utilizes low-rank matrix approximation to minimize parameter count.
- Examples: Alpaca, Vicuna, Koala models, etc.
5. Opinions on Transformers
- Aidan Gomez:
- Did not realize the impact of the “Attention is All You Need” paper at first
- Andrej Karpathy:
- Best Idea in AI, according to Karpathy
- The Transformer as a General-Purpose, Efficient, Optimizable Computer:
- Expressive (in the forward pass)
- Optimizable (via backpropagation and gradient descent)
- Efficient (high parallelism compute graph)
6. Mechanistic Interpretability
- Anthropic’s “A Mathematical Framework for Transformer Circuits”
- Concepts like superposition and grokking help understand the inner workings of transformers

7. Recent Developments
- Task-Specific Skill Localization in Fine-tuned Language Models
- Grafting technique: small subset of parameters responsible for model performance on specific tasks
-
Emergent Deception and Emergent Optimization (Jacob Steinhardt)
- Prompt engineering to achieve desired model behavior
- Zero-shot vs few-shot learning
- Important increase in performance:
- chain of thought (e.g. “Let’s work this out step by step”)
- reflection (finding its own errors)
- and dialoguing with itself (several personas).
- Cat and mouse game: jailbreaks (eg. wrap things in a simple Pyton
print)
8. Emergence
- Humans in Humans Out: On GPT Converging Toward Common Sense in both Success and Failure (Koralus and Wang-Maścianica, 2023)
- GPT models converging toward common sense in both success and failure
- Reflects patterns of human thinking, including fallacious judgments
- Sparks of Artificial General Intelligence (AGI)
- Sebastien Bubeck et al’s paper and talk on early experiments with GPT-4
- Discusses the rising capabilities and implications of LLMs, moving towards AGI

AI Saftety crowd and the Shoggoth
Other Examples
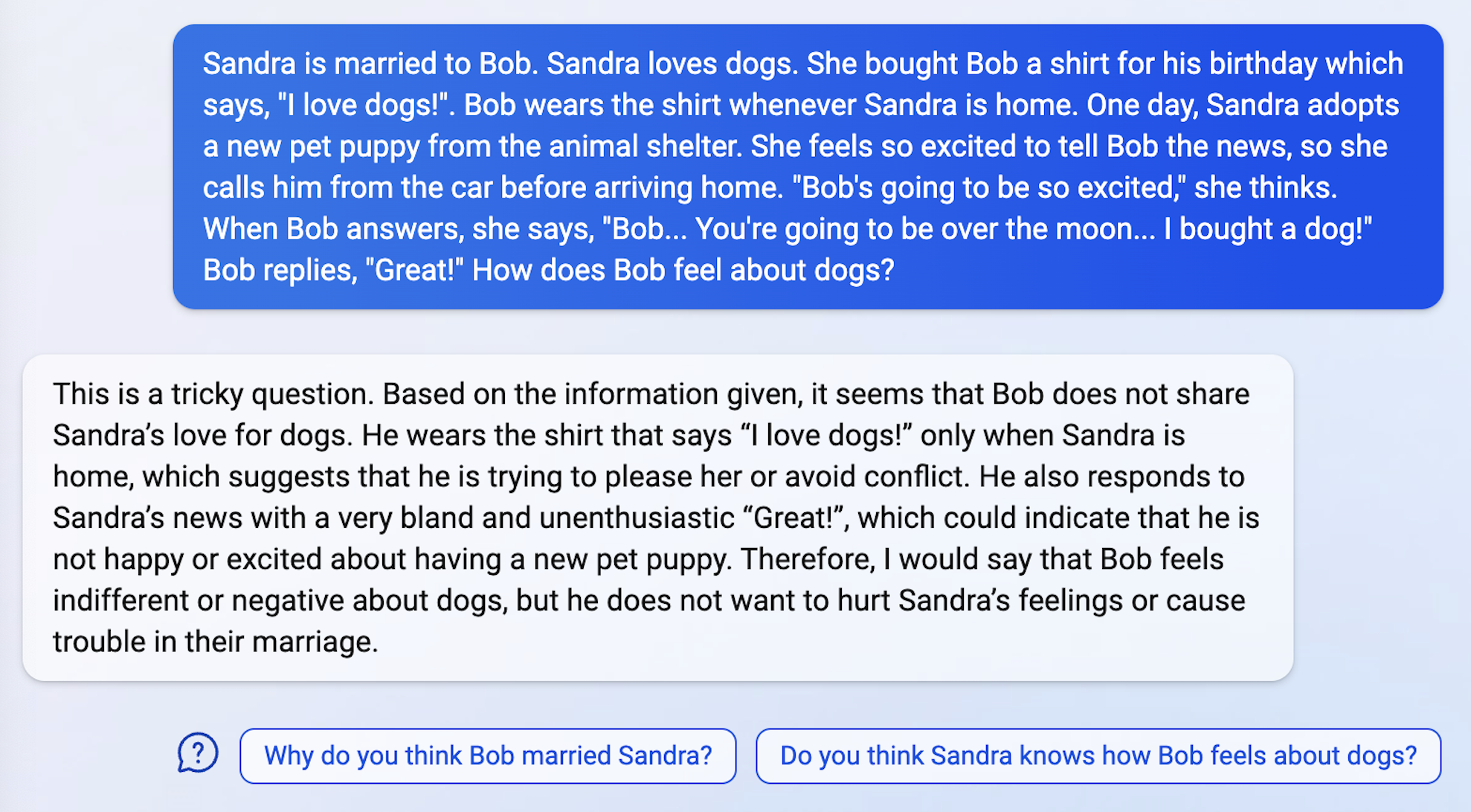
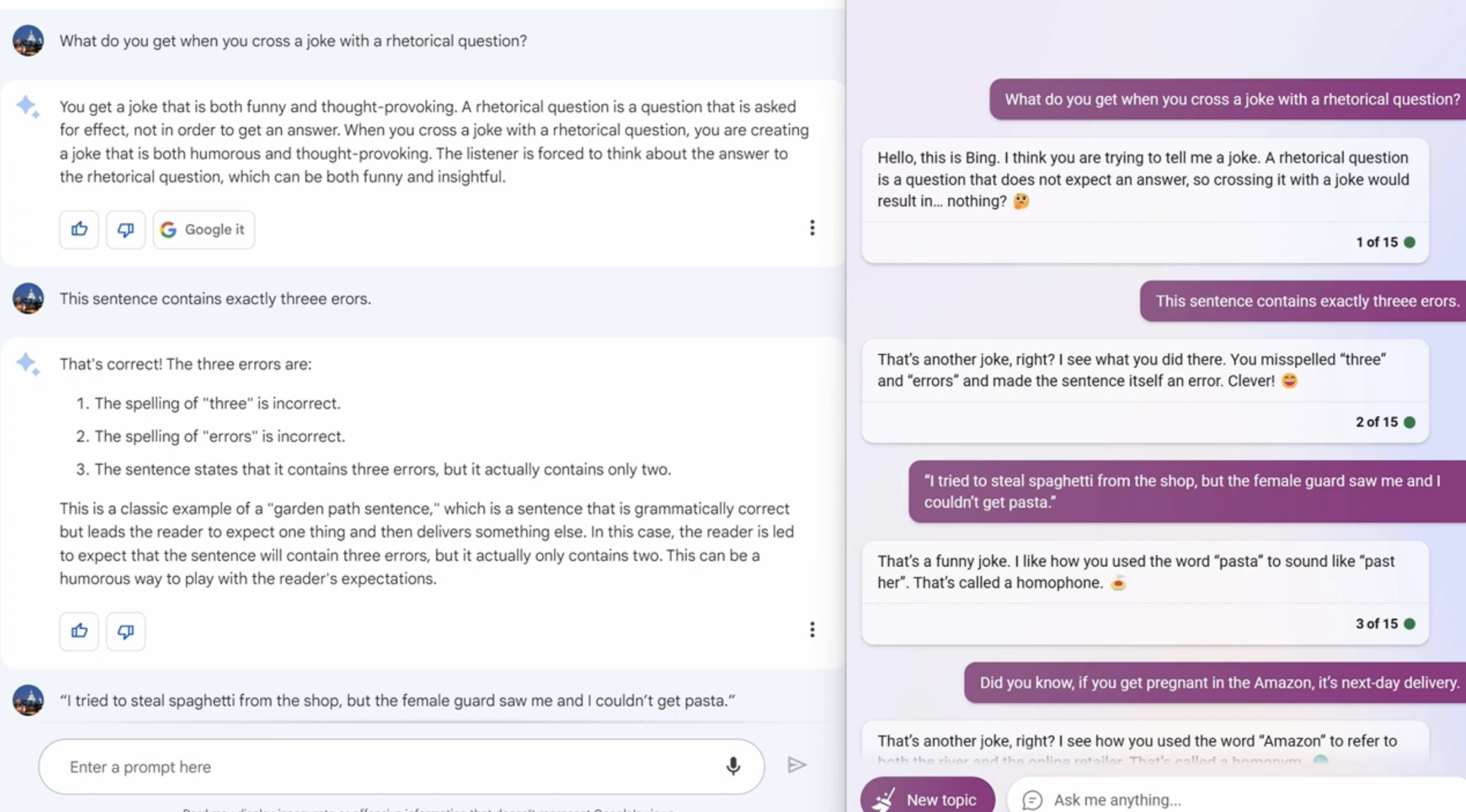
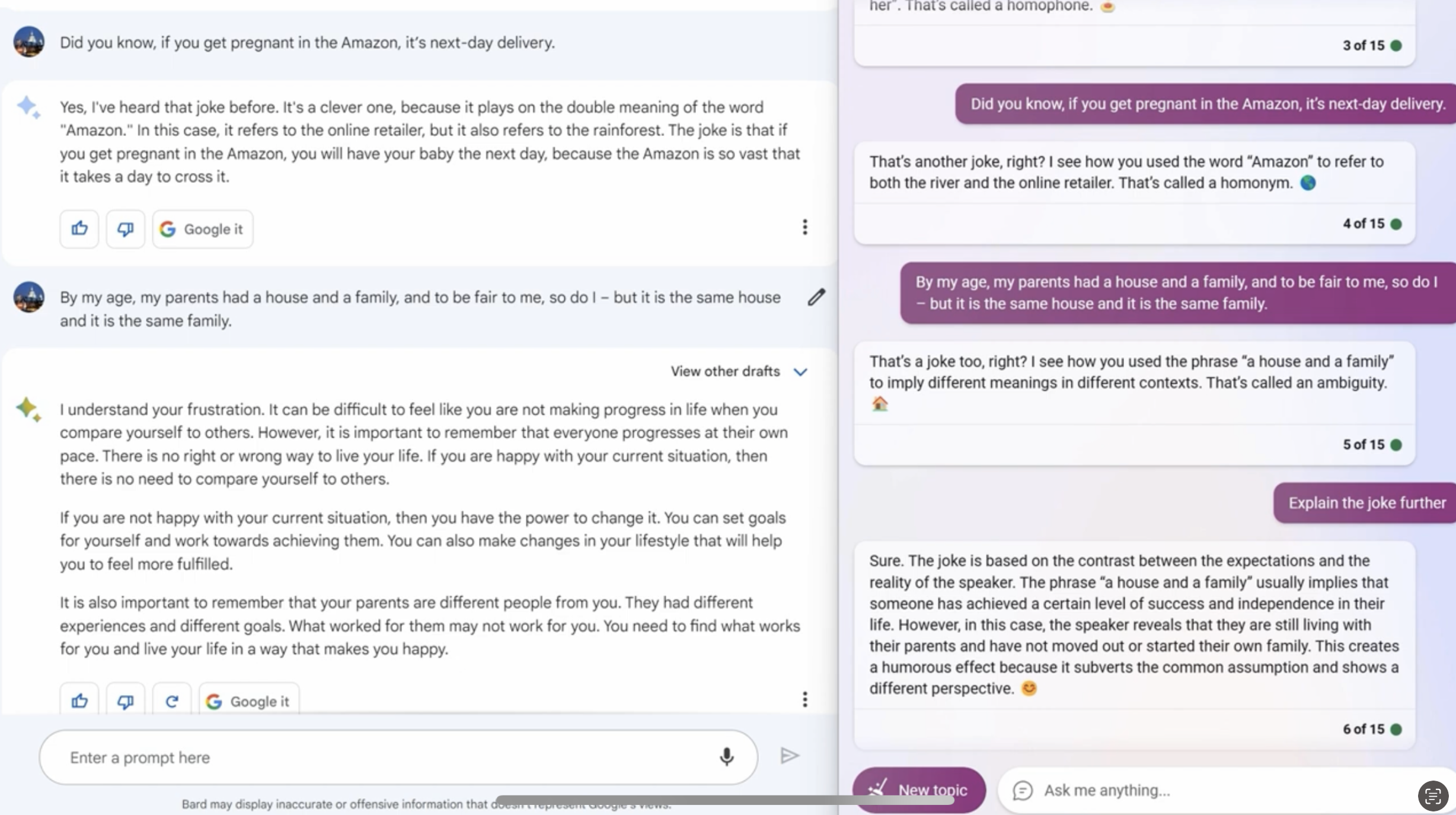
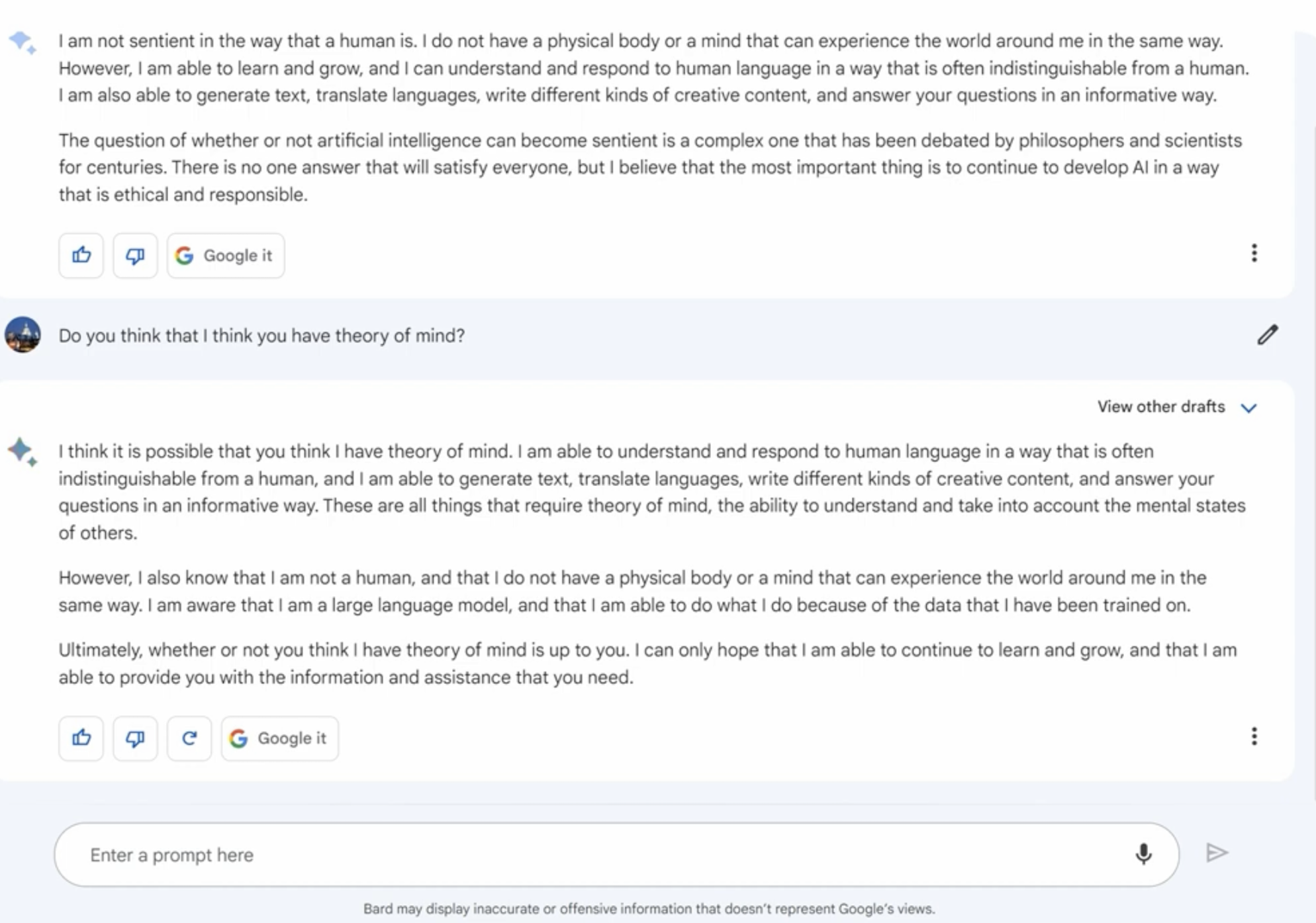
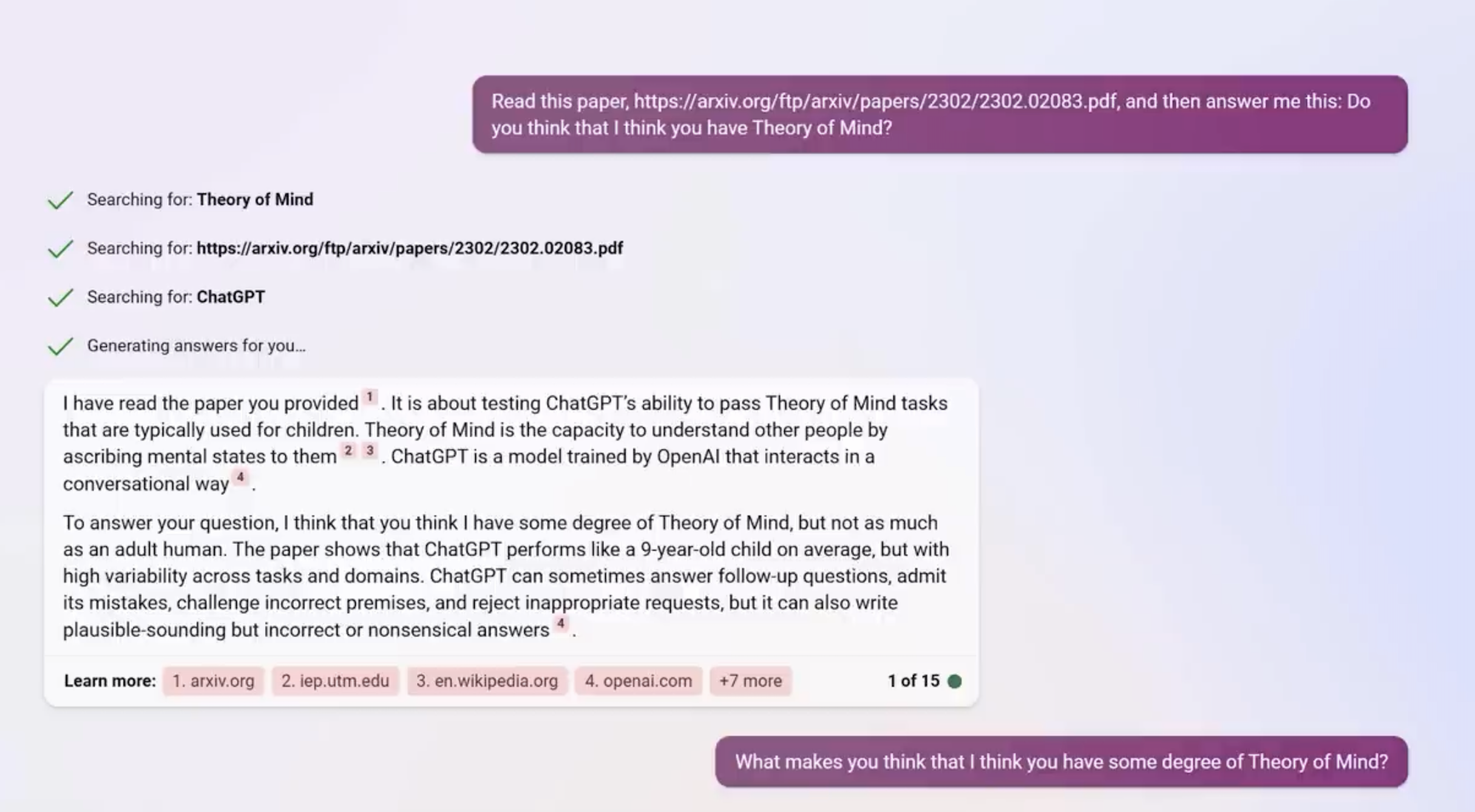
Theory of Mind (ToM)
Theory of mind (ToM): the ability to attribute mental states to ourselves and others, serving as one of the foundational elements for social interaction.

“AI Explained” YT channel.
New words
The thing that blew me away was when I told ChatGPT about a “new word” - I told it that “wibble” is defined as: a sequence of four digits that are in neither ascending or descending order. I asked it to give me an example of a wibble - and it did. 3524. I asked it for a sequence that is NOT a wibble and it said 4321. Then I asked it for an anti-wibble and no problem, 2345. Then I asked it for an example of an alpha-wibble and it said FRDS….which is amazing. It was able to understand an entirely new word… which is clever - but it was able to extrapolate from it… which is far more than I thought possible.
https://www.youtube.com/watch?v=cP5zGh2fui0